
#106- When AI meets database
Shift from traditional databases to AI-first solutions to see emphasis on compute-driven pricing, AI integrations, and improved developer experiences
AI x DB
The role of databases is shifting from a utility in the background to a critical enabler of modern AI-driven workflow. Traditionally, databases operated as the silent workhorses of software systems—responsible for reliably storing, retrieving, and managing structured data. Their pricing models were built around this static, predictable reality. You paid for how much data you stored and how often you accessed it. That paradigm made sense in an era of transactional systems, static reports, and gradual data growth. But the explosion of AI-first applications has exposed the cracks in this legacy foundation.
Generative AI (GenAI), real-time inference, and embeddings have redefined what a "database" should do. These workloads aren't about storing data—they’re about activating it in real-time. AI models like GPT-4 synthesize data from multiple sources, requiring millisecond-latency queries and access to unstructured data.
Vector embeddings, key to AI search and recommendations, need new indexing and retrieval methods that legacy databases weren’t built for.
AI-first startups are deploying models on dynamic datasets, needing systems that handle real-time ingestion and schema updates. This shift is changing user expectations.
Legacy pricing models can't keep up
Traditional databases were priced based on storage capacity (terabytes) and access frequency (read/write/query costs). For AI workloads, these metrics don't matter. The focus is on the computational intensity of transforming data into insights, not dataset size. Storage-based pricing penalizes large datasets with low computational needs, while access-based pricing discourages real-time experimentation—vital in AI workflows.
The AI Era- speed, scale, and new demands

GenAI is about speed and scale. Companies aren’t just storing data—they're integrating it into neural networks, optimizing for machine learning, and deploying it in live systems. This brings new challenges:
GenAI workloads are compute-heavy, consuming vast resources to fine-tune large models or process embeddings
Real-time demands are critical- AI-driven applications like customer support or personalized recommendations can’t tolerate latency
Scale is exponential- AI systems grow rapidly, meaning database architectures must scale dynamically to keep up
Databases are becoming active participants in computation, forcing providers to rethink pricing, architecture, and strategy to meet the needs of an AI-first economy.
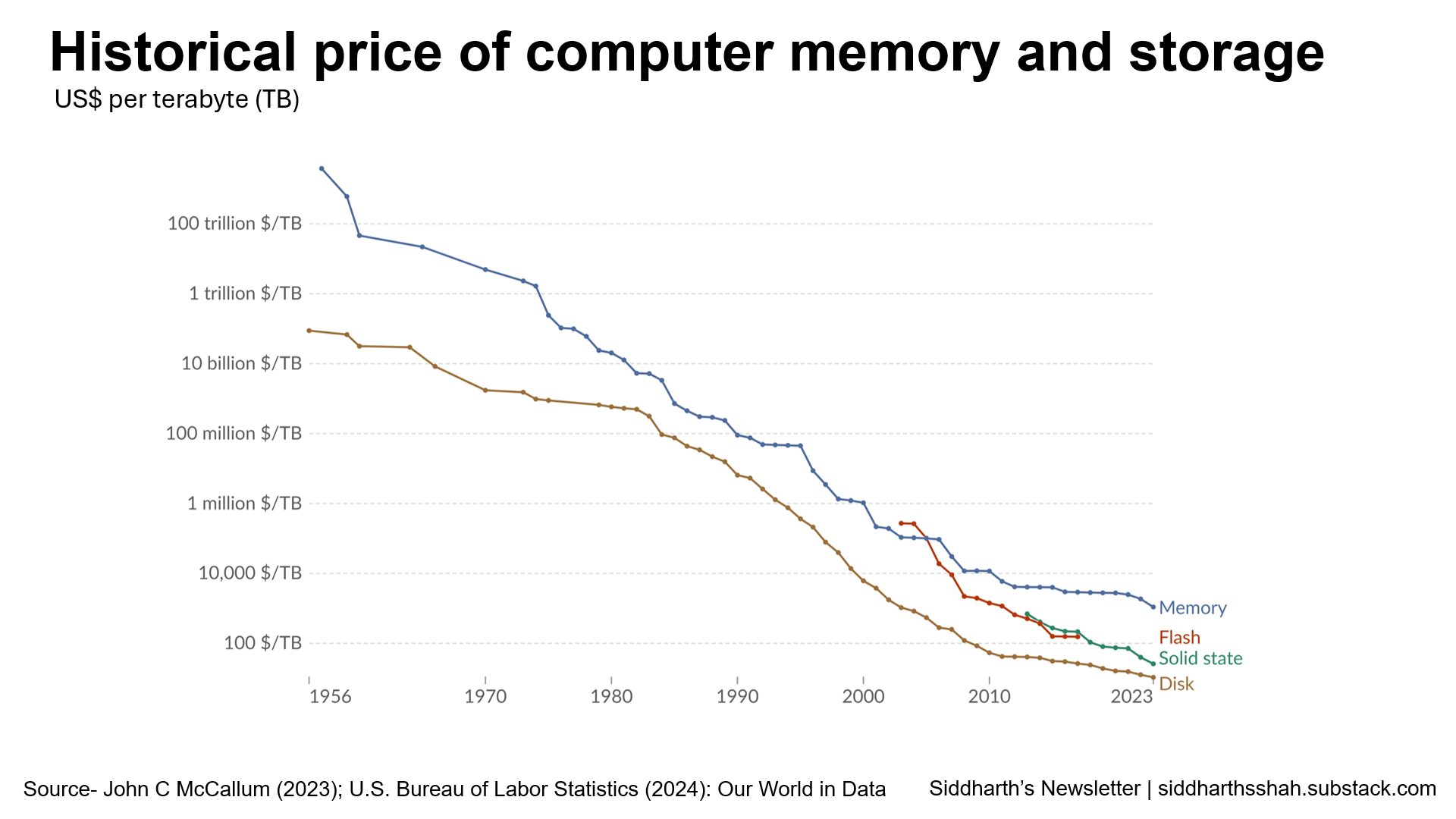
The free database era
Storage costs near zero- Storage is no longer a differentiator; it's a commodity. Hardware advances and cloud scale have driven the cost of storing data to near zero for the average user.
Hardware efficiency- Storage technology has slashed per-TB costs.
Cloud scale- Giants like AWS, Google, and Azure operate at massive scale, subsidizing storage costs for developers in exchange for higher-margin services.
Demand elasticity- As costs drop, data grows exponentially. Companies now store everything from transactions to logs and interactions.
Storage is table stakes. The real game is in what you do with the data.
Honey pot- Offer free databases to attract developers
Free databases are a key funnel strategy. By removing barriers, providers can integrate early into developers' workflows, creating lock-in through network effects.
Developer mindshare- A free database becomes the first choice for testing, prototyping, and scaling.
Ecosystem expansion- Companies like MongoDB and Cockroach Labs offer free tiers with plans to monetize via advanced features or enterprise support.
Lifetime value (LTV)- Early adoption locks developers in, creating technical debt that makes switching costly.
Free is about positioning for downstream monetization through performance upgrades, AI integrations, and compute. In the AI world, the database is becoming the bait.
The real business model is Compute + Integrations
AI-first applications have reshaped how we view databases, not as simple storage, but as active players in computation-heavy workflows. The real drivers of revenue today are compute and integrations.
Compute is the new pricing lever
AI workloads demand heavy computation. Traditional databases were built for predictable CRUD (create, read, update and delete) operations, but AI requires things like vector searches, real-time model inferences, and streaming analytics, all needing immense computational power. Databases now do more than store data, they process embeddings, rank results, and manage complex queries at massive scales.
Users now pay for performance, not storage. Storage is cheap, but time isn’t. Developers will pay more for faster results, lower latency, and optimized compute pipelines. Pricing models are shifting from per GB stored to per compute cycle, based on operations like queries and batch inferences. This creates a flywheel effect: better performance means more usage, which means higher pricing power.
Database-native AI ops
Vector search is central to AI applications, requiring databases to handle dense vectors, prioritize recall, and scale across billions of items. Companies like Pinecone, Weaviate, Qdrant etc have shown the demand for these systems, and traditional vendors are quickly catching up. Features like vector indexing and sparse matrix computation are becoming essential for AI-first databases.
Compute pricing aligns with the resources these features consume. The more you query, the more you pay…but that's because the infrastructure ensures peak performance.
And this has started playing out…
#118- The AI meets DB wave is here

When I first wrote about the AI x DB shift earlier in Jan this year, it was mostly a forward-looking thesis. I was seeing cracks in the old database model which still had storage-based pricing, limited compute, legacy ops. I was reading, thinking, and spotting early signs of something new- databases built not just to store data, but to activate it.
What’s next for databases?
It is all changing, stat
Databases are no longer just about storing data—they’re now computational engines, optimized for AI-first workloads. This transformation is driven by real-time processing needs, diverse data types, and the rise of AI.
Two defining trends are shaping the future of databases are edge-cloud symbiosis and multi-modal capabilities.
Edge-cloud symbiosis- Databases are everywhere!
Data is no longer centralized. IoT, real-time AI, and low-latency demands are pushing databases closer to the edge while leveraging the cloud for scale and analytics.
Hybrid setups- Databases will seamlessly operate on both edge devices and in the cloud. The edge handles fast, local data processing, while the cloud supports deeper analytics and long-term storage.
Speed as a feature- Sub-millisecond query times at the edge will become standard, with the cloud managing tasks like batch processing and model training.
AI at the edge- Databases optimized for vector storage and retrieval will enable AI inference directly on edge devices, powering use cases like autonomous systems, smart cities, and retail.
Multi-modal capabilities- Data systems are unified!
Modern data isn’t just rows and columns, it’s images, videos, streams, and vectors. Traditional databases weren’t built to handle this complexity.
Unified platforms- Future databases will support multiple data types in one system, enabling seamless querying of relational data, embeddings, and geospatial data.
AI-native design- Built-in support for vector embeddings will allow fast similarity searches for recommendation engines, NLP, and anomaly detection.
Integrated workflows- New databases will eliminate painful ETL setups by integrating directly into AI pipelines, streamlining model training and deployment.
Implications for database companies
The AI-first era is reshaping the database industry. Traditional storage-focused models are becoming obsolete as cloud providers drive down costs. The future lies in computational services, not just storage.
From storage to compute- Companies must focus on offering computational power for tasks like vector search, model inference, and real-time data processing. Revenue models will shift from storage fees to compute-optimized services.
R&D priorities- Traditional query performance isn’t enough. Databases need to handle high-dimensional data, support fast indexing, and enable real-time, low-latency access for AI workloads. Distributed systems will be critical for scaling.
Differentiation is thy strategy
Database companies must adapt by focusing on specialized optimizations and seamless AI integration.
Specialized optimizations
Real-time processing- Support instant recommendations and AI inference for use cases like retail and autonomous systems
Batch processing- Efficiently handle massive datasets for tasks like model training using parallel computation
Hybrid models- Offer databases that excel in both real-time and batch processing to cover a wider range of AI workloads
Proprietary AI tools
Machine learning integrations- Simplify model training and deployment with native connections to AI frameworks
AI-native APIs- Provide pre-built APIs for enterprise tools like Salesforce or SAP, enabling seamless integration
Simplified workflows- Abstract complexities to boost developer productivity and accelerate AI adoption
What this means for
Developers- Expect simpler APIs and SDKs that reduce friction in building AI-powered apps
Enterprises- Benefit from faster insights, lower latency, and reduced data transfer costs
Startups- Explore opportunities in niche databases optimized for specific workloads, like healthcare imaging or edge AI.
Opportunities for founders in the AI x DB era
Founders have three key opportunities to lead- verticalized AI-first databases, bundled compute pricing, and enhancing the developer experience.
Niche AI-first databases & vertical & industry-specific Solutions
AI adoption across industries requires specialized databases. Founders can target sectors like healthcare, finance, retail, and logistics, which have complex, regulated data needing real-time processing. Here success comes from designing databases that store and integrate data while providing AI-driven insights for each vertical's unique needs. For example-
Healthcare- Databases integrating patient records, imaging, and genetic data for predictive analytics
Finance- Databases optimized for real-time trading and fraud detection
Retail- Databases supporting recommendation engines, real-time updates, and predictive analytic
Verticalized compute pricing- bundle AI with dbs
Database pricing is shifting from storage to compute and AI insights. Founders can bundle storage, compute, and AI models for specific industries. This model allows for more predictable, usage-based revenue while offering more value than traditional databases.
Bundling- Customers pay for both data storage and compute resources to process and analyze data
Domain-specific bundles- Combine storage, compute, and AI models for sectors like finance (eg. fraud detection)
AI-powered automation- Automate resource allocation and predict compute needs
Enhanced developer experience by simplifying AI integrations
AI integrations are complex, creating an opportunity to simplify database connections with AI/ML models, vector search, and real-time processing. Simplifying the developer experience can drive adoption and set products apart in a crowded market
Low-code/no-code platforms- Allow non-technical users to configure AI databases easily
Pre-built integrations- Offer integrations with popular AI frameworks
Developer toolkits- Provide tools like query optimization, monitoring, and automatic scaling
What’s next?
As databases become free, competition, value creation, and long-term sustainability for database companies are more complex. Here are the risks and open questions as we move towards an AI-driven database future:
Price wars & race to the bottom- Free databases attract users but risk driving prices to unsustainable levels. While storage costs may approach zero, the real value lies in compute. If companies compete on compute prices to dominate infrastructure, margins will shrink, leaving only capital-efficient players standing. This could stifle innovation, making it hard for companies to reinvest in R&D and pushing database functionality into stagnation with only incremental improvements.
Customer lock ins and closed ecosystems- As databases shift to a free model, lock-in will likely be driven by AI integrations rather than storage. Custom AI workflows could make migration harder, locking customers into specific database providers. Cloud giants may create closed ecosystems where switching costs are too high. This raises the question whether the AI database world be dominated by closed ecosystems, or can open-source, modular systems thrive, giving customers more flexibility?
Many thanks to Abhay for sharing his insights and helping me understand the intricacies of the space