
#107- Unstructured data: from RAGs to riches
How RAG (Retrieval-augmented generation) transforms unstructured data into actionable insights, addressing challenges in governance, scalability, and integration in AI

There are two types of data which can be synthesized as-
Structured data– this has a standardized format, typically tabular with rows and columns: text, numerical data, time series, event data, etc.
Unstructured data– this has an internal structure but does not contain a predetermined order or schema: images, audio, videos, 3D assets, etc.
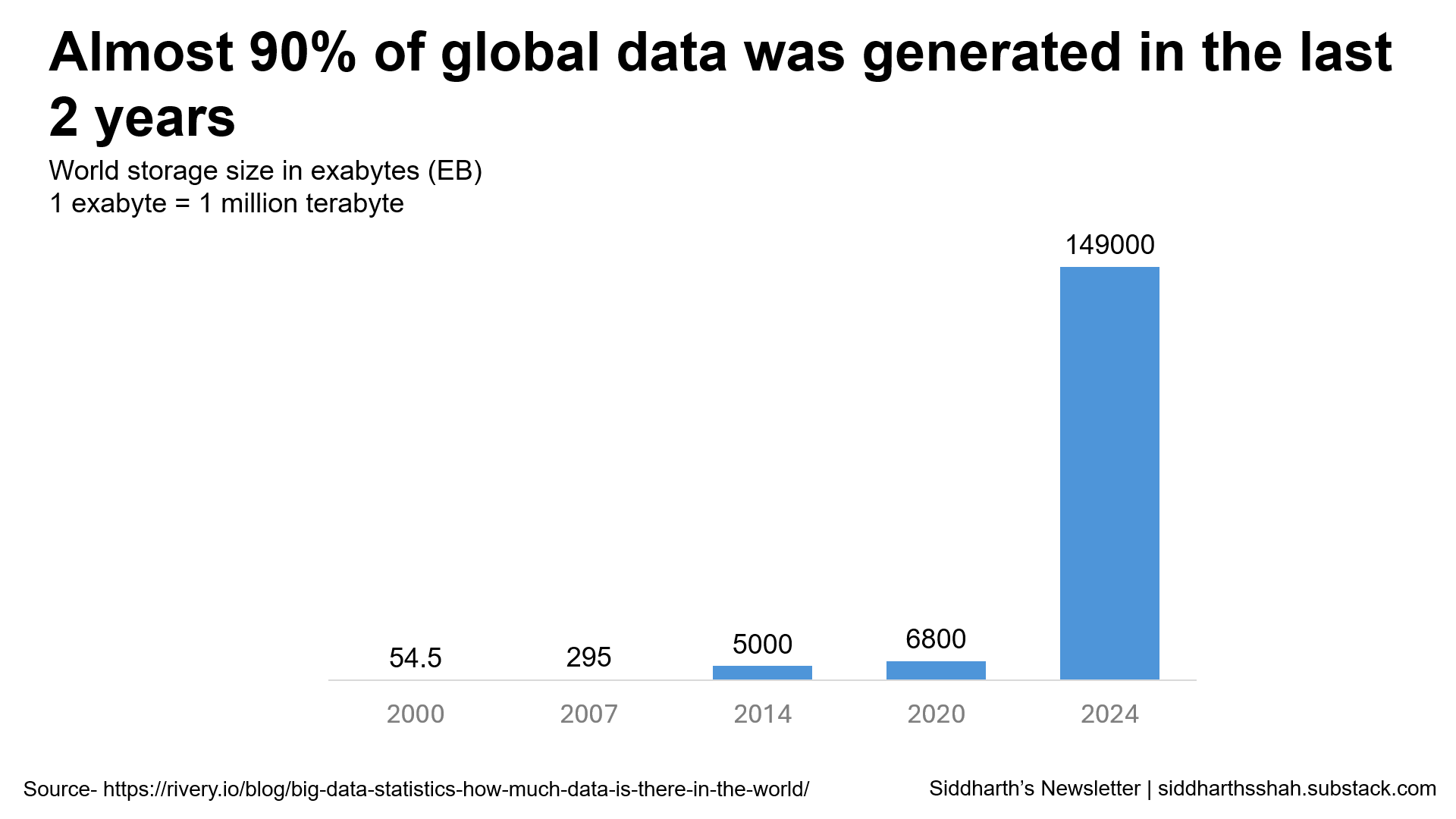
Unstructured data is a huge untapped resource. 90% of all data today falls into this category. That’s a lot. It means most companies have this goldmine they don’t even realize or know how to use. But why? Maybe it’s the complexity of unstructured data as it has no fixed format. Traditional analysis methods struggle with it. Is the issue technical or just that organizations aren’t adapting?
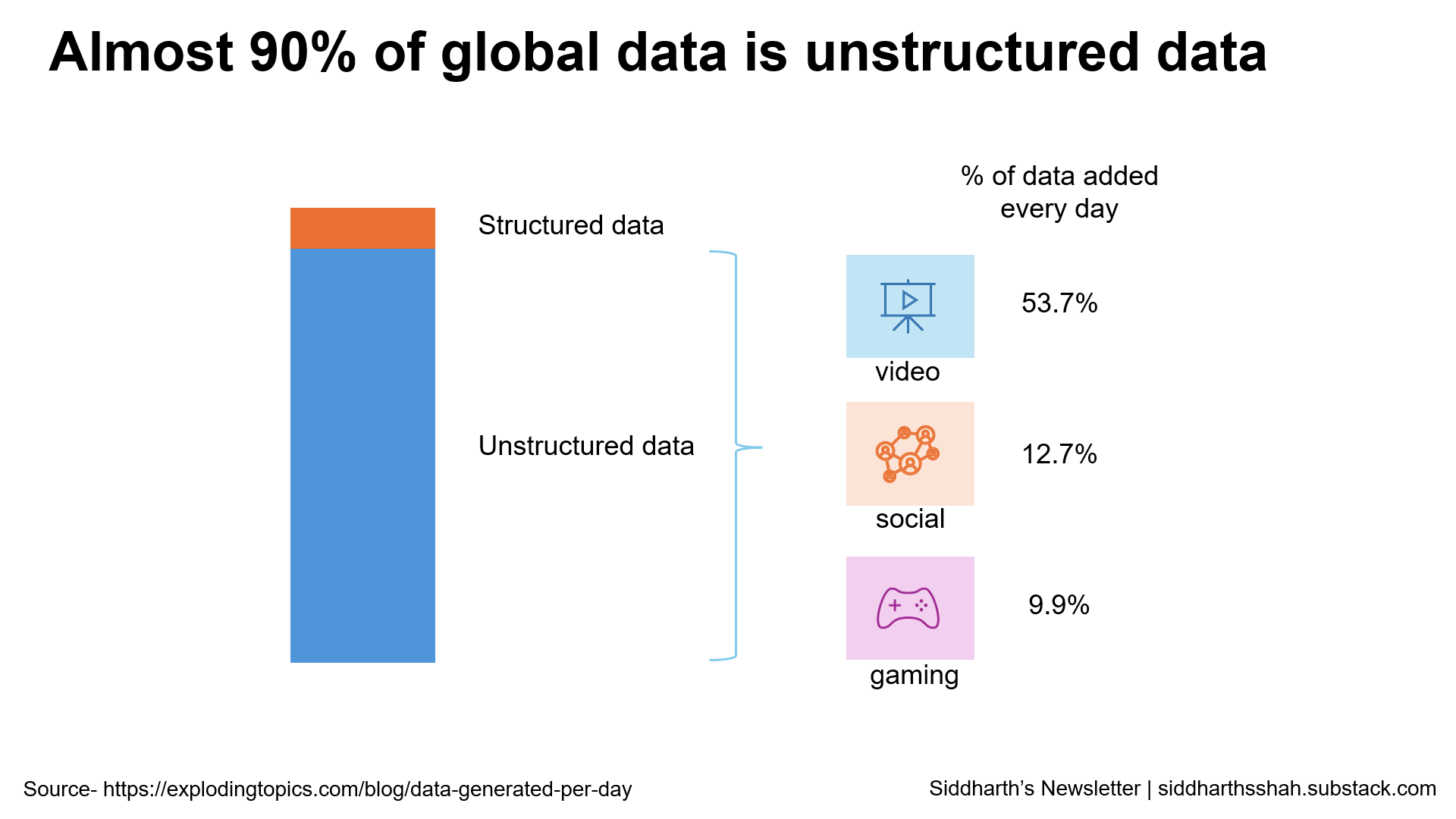
If it’s a technical issue, things like AI, ML, and NLP should already have fixed it. But have they? Somewhat. We’re seeing things like sentiment analysis, personalization, and market insights becoming easier. But there’s a gap. Old methods fall short when the unstructured data gets too big or varied. That’s where Generative AI (GenAI) comes in. But GenAI is not the answer to everything. It still has problems like hallucinations, security risks, and the high cost of training and fine-tuning models. That’s worrying. Even the latest tech doesn’t seem to fix all the issues.
Enter RAG
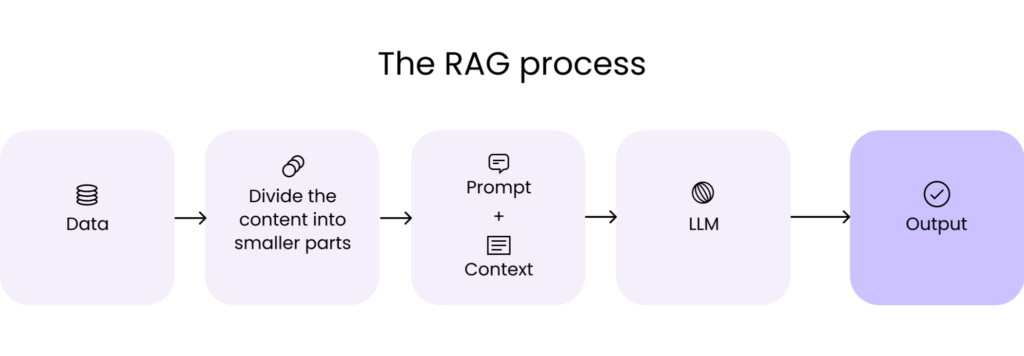
RAG or Retrieval-Augmented Generation, combines retrieval with generative models to fix some gaps in LLMs. LLMs are great at generating text but can get things wrong. They might make stuff up or hallucinate or fabricate data, especially when they don’t have the right context. RAG tries to fix this by grounding its responses in external, retrieved information. But does it really solve the problem, or just add more complications? If it works well, it should make the output more reliable. But I wonder if the retrieval process itself could introduce new issues. Does it always pull the right data? Or could it bring in irrelevant or conflicting information that messes things up?
Using RAG to unlock unstructured data
The real game-changing aspect is how we integrate it with other systems to overcome its limitations. This leads directly to RAG. By combining LLMs with retrieval mechanisms, RAG effectively grounds generative outputs in real, relevant data. But how exactly does this work? The process of retrieval, augmentation, generation seems straightforward, yet its effectiveness hinges on several factors. Data preparation, model selection, and system integration all need to align perfectly.

If RAG systems require meticulous data preparation and fine-tuning, does that make them impractical for smaller organizations? Not necessarily. Techniques like semantic search and modular RAG frameworks promise cost-effective implementations. Still, the initial setup might be a barrier. Maybe cloud-based solutions or pre-built frameworks lower this threshold?
The security angle is also critical. Unstructured data often includes sensitive information, so robust access controls and compliance mechanisms are non-negotiable. RAG addresses this by grounding responses in data the user is authorized to access. That’s reassuring but also raises a new question, how do we ensure these systems remain secure as they scale? More data means more points of vulnerability. So is this a bottleneck or just another challenge we can solve iteratively?
Challenges of unstructured data in GenAI
Unstructured data isn’t plug-and-play. To prepare it for AI, you need to clean, tokenize, normalize, and vectorize it. Each step introduces complexity and potential error. For instance, cleaning involves removing noise, but what counts as "noise" often depends on subjective judgment. Tokenization. i.e. breaking down text into smaller units, can lose context especially in languages rich with nuance. Already even before AI processes the data, much of its richness ‘might’ be filtered out.

Then there’s the security angle. Feeding unstructured data into Large Language Models (LLMs) risks exposing sensitive information. Consider internal emails or customer chats. If these leak, whether through negligence or malice, the fallout could be severe. But even if data stays secure, we still may face hallucinations in LLM output. Why? Because models infer based on probabilities, not facts. Without proper grounding, they fabricate.
The benefits of using unstructured data in GenAI seem undeniable. We get better insights, improved decision-making. However, the risks still exit. The solution may lie not in avoiding these challenges but in addressing them head-on. Frameworks like RAG, which ground AI responses in external, verified data, offer a path forward. Yet we’ve questions like how scalable is RAG? How feasible for smaller enterprises? It’s becoming clear that the value of unstructured data in GenAI hinges entirely on how organizations navigate its complexity.
So what makes RAG unique?
First, retrieval. RAG retrieves relevant external data like text documents, images, or other unstructured formats before generating a response. This retrieval adds a factual grounding layer, which feels critical for applications requiring accuracy. But retrieval alone isn’t enough; augmentation is the real pivot point. The system combines the retrieved data with the user query, creating a richer input for the generative model.
Now, the generation phase, the LLM, uses this augmented input to craft a response that is both informed and contextually aware. This hybrid process seems elegant on paper. But it raises a question: how seamless is the integration of retrieval into generative workflows? For instance, does the augmented context ever overwhelm the model, leading to overly verbose or irrelevant responses? Also, what about real-time scenarios where retrieval must happen instantaneously?
Where does RAG shine?
Content generation, chatbots, and search engines immediately come to mind. These areas thrive on accurate, context-specific outputs. In search engines, for example, RAG can transform generic queries into answers enriched by external, domain-specific knowledge. But another question: are there diminishing returns in cases where retrieval sources are sparse or of poor quality? And in content generation, does RAG strike the right balance between creativity and factual accuracy?
Why choose RAG?

Reduced hallucinations
Hallucinations (i.e. fabricated facts) are a known issue with LLMs. By grounding outputs in retrieved data, RAG reduces this risk. But does this fully eliminate the problem? If the retrieval sources themselves are flawed, wouldn’t the grounded response still propagate errors? It feels like RAG’s effectiveness hinges entirely on the quality of its retrieval pipeline.
Enhanced transparency
Cited, verifiable sources build trust. That’s a major win. Still, I wonder: how transparent is too transparent? If responses are cluttered with citations, does that harm usability? And what happens when proprietary or sensitive data is cited, how is this managed?
Cost efficiency
Leveraging existing LLMs rather than training new models is resource-efficient. But again, a question: does RAG’s upfront complexity offset this efficiency in any way? Building a robust retrieval system and vector database isn’t trivial
Improved security & compliance
Role-based access controls ensure only authorized data is used. This is vital for enterprises. But compliance is a moving target, especially with global regulations. Maybe RAG could also adapt retrieval pipelines for region-specific compliance needs like GDPR or DPDP
Maximized ROI on GenAI initiatives
By integrating existing tools with minimal additional training, RAG seems ROI-friendly. Now, this does assume a smooth implementation. But we’ve to look for hidden integration costs or unforeseen technical hurdles that reduce ROI. By doing this, it solves the biggest problems facing GenAI initiatives - privacy and transparency

While RAG appears to be a significant step forward, its complexity introduces a need for thoughtful implementation. Its real potential lies in how well enterprises can align the technology with their unique data ecosystems.
How can we implementing RAG?
RAG combines retrieval and generative capabilities to handle unstructured data. The process breaks down into three steps: preparation, model selection, and integration. Each requires careful attention.
Preparation is about making unstructured data usable. Vector databases and knowledge graphs help streamline preprocessing. Semantic search can cut costs by making the process more efficient.
Model selection is tricky. When should you choose a modular framework over a simpler approach? It depends on the task's complexity and accuracy needs. But complexity is subjective, and defining it can be tough.
Integration seems straightforward, but integrating RAG with existing LLM pipelines is never seamless. How well the workflows adapt is another consideration.
While the steps seem clear, the real challenge lies in executing them well.
Best practices for RAG
This focus on governance and quality control. But what does governance really mean? It’s about managing metadata, tracking lineage, and enforcing policies.
Scalability is another critical factor. Cloud-based architecture doesn’t always guarantee scalability, there can be limitations to consider. And security must be balanced with accessibility. Robust access controls are crucial, but how do you ensure users can still access what they need?
These best practices are valid, but implementation is where things get tricky. If data sources are unreliable, RAG won’t deliver accurate results. It’s the classic garbage in garbage out. The quality of inputs is just as important as the system itself.
Some concerns (maybe due to my lack of technical ability)
One concern keeps nagging me- can RAG truly reduce hallucinations as claimed? While grounding LLM responses in factual retrieval sounds promising, might there still be edge cases where RAG fails to provide accurate data? If RAG's reliance on accurate external data is its strength, does it become a liability in situations with limited reliable data sources?
Another potential pitfall is the assumption that RAG pipelines are cost-efficient by default. If preprocessing involves complex multimodal data or extensive knowledge graphs, does this not risk offsetting the supposed cost savings?
While the technology promises transformative benefits, its success hinges on nuanced execution, especially around data governance, reliable inputs, and careful model selection.
The potential!
The transformative potential of RAG lies in its ability to unlock unstructured data's immense value for enterprises. By combining retrieval and generative AI capabilities, RAG bridges the gap between messy, unstructured data and actionable insights. However, success hinges on thoughtful execution: rigorous data preparation, precise model selection, and seamless integration into existing workflows.
Best practices such as prioritizing governance, emphasizing reliability, and designing for scalability can make or break RAG implementations. Ultimately, RAG is not just a tool but a strategic enabler. Enterprises must approach it holistically, positioning unstructured data as the cornerstone of their GenAI strategy to realize its full potential.