
In Part 1 of this series, I shared my thoughts on why I feel automated data preprocessing is step 0 of the AI ModelOps process. But getting the right data ready is not everything, what happens when things go wrong?
In the rush to build smarter models and faster pipelines, most teams skip one critical question, "What’s our rollback plan?" Not for the codebase, for the data. For the models. For the experiments. For everything downstream of that one corrupt file or mislabeled feature or wrongly added weight.
Welcome to The AI ModelOps Trifecta - Part 2: Automated Data Backup & Recovery. This is the most underappreciated pillar of AI infrastructure. If preprocessing is about quality going in, this is about resilience when it all comes crashing down. And as we move towards continuous training, multi-cloud storage, and regulatory scrutiny, it’s no longer optional.
2. Automated Data Backup & Recovery
We're so excited to build AI models that we easily overlook the mundane and soul sucking aspects like data backup & recovery. Almost everyone of us have our gmail, phone and laptop memories full but I dont think we're on top our backups. Its okay to lose 10000 emails and 500 screenshots we're never going to read or refer to again. But for an enterprise running itself on an AI model, losing data means staring at death.
Each aspect of an AI model from ingestion to training to testing to deployment will generate massive amounts of data - think raw data, cleaned data, model logs, what not. Here, traditional backup methods are struggling to keep up.
Can you recover a corrupted 5PB training dataset quickly?
Can you roll back a model with wiped weights?
Do you even know what data version trained what model?
Many organizations dont, and they’re one bad script away from disaster. Or maybe they rely on ad-hoc scripts for copying files, which is fragile and risky. Also, AI data often lives in the cloud, and data lakes, is distributed across regions and not neatly managed like databases of the past. This introduces new challenges for consistency and governance.
Data is the lifeblood of AI-driven businesses, and any downtime or loss of data can be disastrous. While regulated industries like finance, healthcare, defence, pharma, etc have strict compliance needs for data retention and recovery, most do not. New regulations (GDPR, emerging AI Act, etc.) also demand accountability and traceability. And that requires preserving historical data and model version logs
At the same time, global data creation is exploding (with IoT, AI, and digitization contributing global data volumes are projected to reach ~175 zettabytes by the end of 2025), putting strain on legacy backup systems. Traditional enterprise backup vendors (e.g. Commvault, Veritas) and newer cloud-era players (Cohesity, Rubrik) service general IT needs, but AI workloads present unique requirements-
Frequent snapshots of evolving data,
Rapid restores for continuous training, and
Integration with ML pipelines
The core pain point is ensuring resilience and continuity for AI data, with minimal manual intervention.
So what is driving this?
Several trends amplify the urgency for modern backup & recovery in AI contexts:
Complex data pipelines & versioning needs: AI data isn’t static, it flows through complex pipelines (raw to clean to training, pardon my nomenclature). Each stage may produce a new data version. Without automated backup/version control at each step, reproducing a model result or recovering from a bad/wrong step is nearly impossible. Companies now recognize that as they move towards complex data lifecycles, they need reliable backup and version control systems. This has led to interest in lineage and version-control tools which snapshot and track data changes.
Ransomware threats: As data becomes a strategic asset, losing is a business continuity and security issue, maybe even mortality risk for the company. The rise of ransomware attacks made data backups a board-level priority. Now AI datasets which might include PII or expensive prop data, are becoming juicy targets. Modern backup solutions which can automatically secure and isolate AI data (for e.g., creating air-gapped backups or using blockchain?? for integrity & identity verification) will be increasingly sought. Many enterprises are re-evaluating their data protection in light of high-profile breaches, creating an opening for innovative solutions. If you have a great product, you’ll see the least friction in sales in/around breaches - but please dont create one as a growth hack!
Cloud native and multi cloud- More AI workloads run in the cloud or across multiple clouds/hybrid setups. Cloud providers do offer basic backup and snapshot tools (AWS Backup, etc.), but these arent cloud agnostic (and most orgs & models are). Enterprises operating multi-cloud or wanting to avoid cloud lock-in are looking for independent, cloud-agnostic backup platforms (another reason I feel this will be a strategic acquisitive play). A trend is towards SaaS backup services which handle data from various sources (SaaS apps, on-prem) in one place. For AI, a backup service that can cover, say, an on-prem and a warehouse and a cloud layer is attractive. Essentially, the bundled cloud-native solutions leave gaps for startups to fill – especially around heterogeneous environments and AI-specific context (e.g. knowing to temporarily make an ML pipeline inactive or coordinate with model registries during backup).
Regulatory whip: Emerging AI governance rules imply that companies must maintain audit trails of their models and data. To audit how an AI decision was made six months ago, you need the exact data that trained that model and possibly intermediate datasets. Automated backup tied to model versioning can enable this level of traceability. Being able to demonstrate regular automated backups, with quick recovery checks a critical box. Thus, the risk of non-compliance (fines, legal issues) is another tailwind pushing organizations to invest in better data backup solutions for AI.
Automated data backup & recovery market landscape
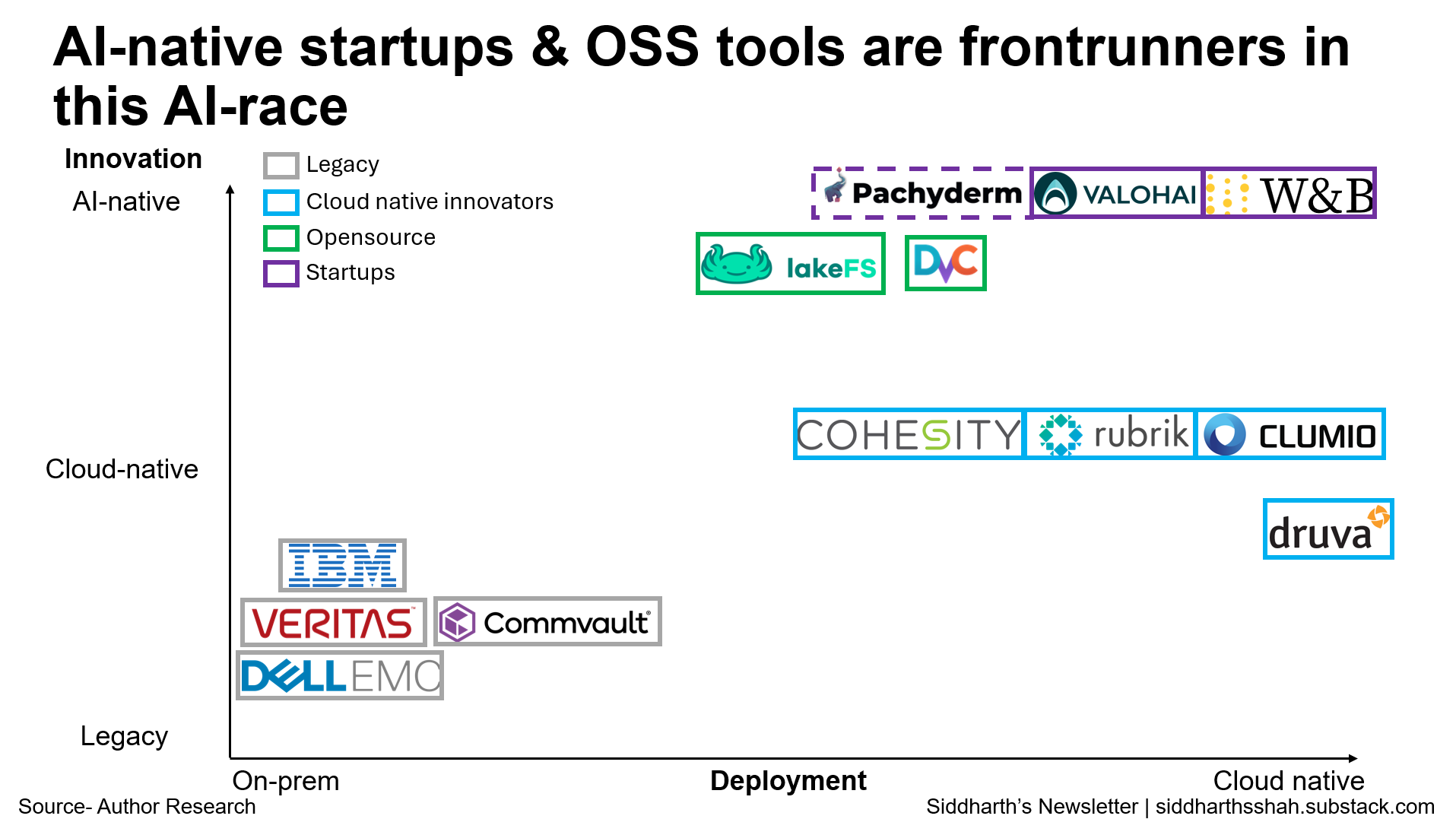
Legacy & incumbent tools - We begin with the battletested backbones of enterprise backup aka the legacy players like IBM & Dell EMC. These are excellent when it comes to traditional workloads like databases, file systems and IT assets. They offer policy control, deduplication, access control, and all the features that a regulated industry requires. But they arent built for the AI-native world. They cant understand model checkpoints, weights, version-based datasets or pipelines. They're geared for on-prem or private cloud setups and require manual configs. They're not purpose-built for AI.

Cloud native innovators- These are modern successors to legacy tools built with the cloud or SaaS in mind. They have sleek UI, API access, deep integrations with cloud providers like AWS, GCP, Azure. These offer simplicity and scale across hybrid environments. Some even offer air-gapped backups and are strong at servicing SaaS apps like backing up Salesforce, Workspace etc. But they fall short of AI-specs. They still cant version models, plug into ML pipes. They're faster, smarter versions of legacy players but not built for ML.

Open source solutions- The OSS layer including tools like LakeFS, Data Version Control (DVC), and Pachyderm is where things get interesting. These were built to give data scientists and ML engineers some form of Git-like control over datasets, models, and pipelines. They’re modular and they solve versioning but don’t offer full-fledged backup or disaster recovery guarantees. They’re not full solutions. Still, they’re increasingly foundational for AI-native teams that care about reproducibility and rollback. And because they’re open source, they’re flexible, extensible, and can be deeply customized.

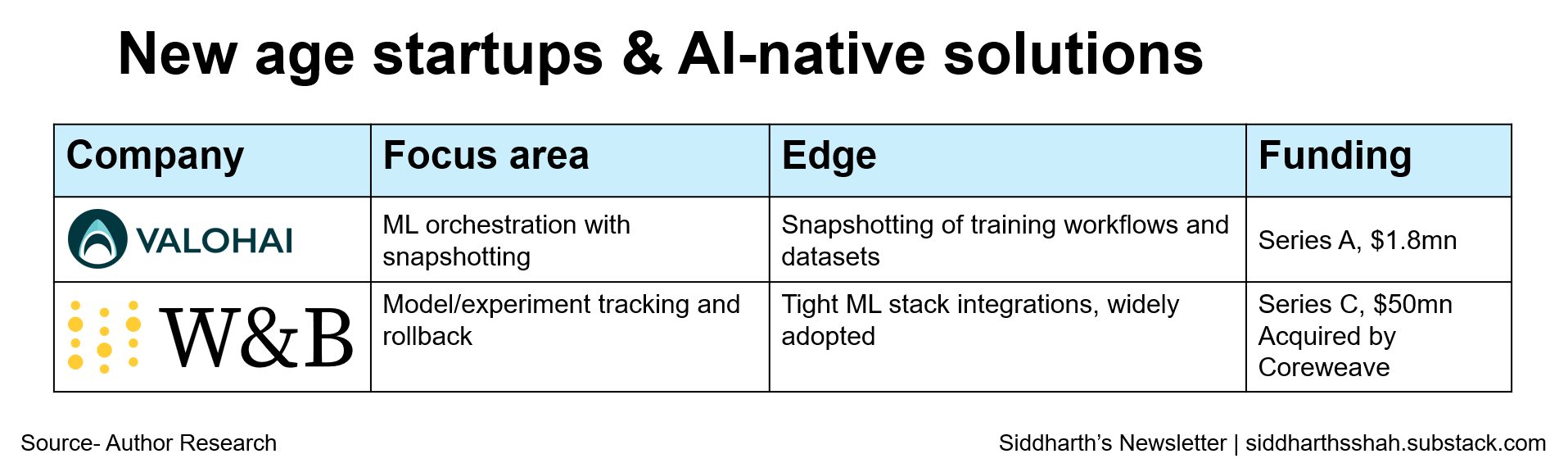
AI-Native Startups- This is the most exciting (and still emerging) category. Companies like Valohai, Weights & Biases are building from the ground up to serve ML workflows. These tools are born from the pain of not being able to roll back an experiment, reproduce a model, or track what version of the dataset trained what version of the model.
What makes them special is that they think like an ML engineer not an IT admin. They’re opinionated, plug directly into pipelines, and offer intuitive rollback and tracking for the things that matter in AI: data versions, model artifacts, metrics, and training configs.
That said, most of them still lack traditional backup semantics. They also tend to focus more on observability than durability. So while they’re not "backup" in the old-school sense, they’re closest to what backup needs to become for AI.
The market is clearly moving toward AI-native resilience where versioning, rollback, and recovery are built into the MLOps fabric, not bolted on afterward.
The most promising opportunity? A new platform that combines the versioning smarts of OSS, the reliability of traditional backup, and the AI-first thinking of W&B and Valohai to create a true "AI Undo Button."
Market Potential
The broader data backup and recovery market is large and growing steadily. In 2025, it’s estimated around $16–17 billion globally, on track to reach ~$29B by 2029 growing at 15% CAGR. This growth reflects strong demand for data protection as data volumes explode. While that covers all data, the subset relevant to AI (big data infrastructure, cloud data) is a significant slice. Virtually every enterprise implementing AI will need to modernize their backup strategy, suggesting a multi-billion TAM just for AI data resilience. Startups in this space can also piggyback on the overall growth in cloud data management. Notably, spending on cloud backup is driving the market – as per reports, cloud-based data backup adoption is a leading growth driver. This aligns with the need for SaaS or cloud-native solutions for AI workloads.
Thesis
To build a compelling business here, a startup should start by solving a hair-on-fire problem that current solutions ignore. One wedge strategy is focusing on model-specific backup – e.g. a service that automatically versions every trained model and its training data, providing an “undo button” for model deployments. This ties into ModelOps directly and could be sold to ML platform teams. Another wedge is targeting cloud AI datasets: for example, a backup solution optimized for data lake files (Parquet, etc.) with delta changes, which legacy vendors handle poorly. By proving themselves in one niche (say, fast restoration of large ML datasets or seamless backup for hybrid cloud ML clusters), the startup can expand horizontally to full data resilience platform.
Lock-in can be achieved through data gravity and integration depth. A backup service, almost by definition, holds copies of a client’s critical data – switching away means moving all that historical backup data, a non-trivial task. Moreover, if the solution integrates deeply with the client’s ML workflows (pipelines, metadata) it becomes part of their process. For instance, an ML engineer might use the platform’s interface to roll back experiments or compare versions, making it more than a backend utility. This kind of workflow integration creates stickiness beyond raw storage.
VCs often ask, “Is this a feature or a platform?” In backup, the counterargument is that while basic backup is a feature, enterprise-scale resilience is a whole product category with its own experience layer. Startups should articulate how their features expand into a broader DataOps platform over time. Perhaps offering analytics on data usage, or policy automation for compliance as a bolt on (I strongly feel governance is a long lost cousin of backup. And also governance has two layers- model and data, I’ll write about it someday, maybe). The endgame vision could be an “AI data trust platform” that organizations use to manage all their critical AI data assets safely. That’s well beyond a single feature and firmly in valuable-platform territory.
Exit
We saw high strategic in the case of automated data preprocessing. Similarly, I feel strategic interest will be strong especially as AI workflows become mission-critical and data becomes a regulated, high-value asset. Established backup/storage companies might acquire niche players to expand into AI Or, a successful startup could ride the wave of data growth to become a major standalone backup vendor of the cloud era. With data being the “new oil,” protecting that data is going to be a business with great demand.
Almost all the big players in the tech ecosystem have made moves to acquire companies that secure, version, or manage AI and cloud data more intelligently.
We’ve already seen it happen:
Hewlett Packard Enterprise acquired Pachyderm & Zerto1
Veeam acquired Alcion2
Commvault acquired Clumio3
Salesforce acquired OwnBackup4
Rubrik acquired Datos IO5
AWS acquired CloudEndure6
These exits signal that platforms are consolidating “trust infrastructure” for AI and that companies offering backup, rollback, or reproducibility features purpose-built for modern workflows are increasingly in-demand.
While automated backup & recovery for AI may not have the glamour of model training, it underpins trust and continuity in AI deployments. This space represents a solid mid-term bet: as companies mature in their AI journey, their focus is shifting from just building models to operationalizing them reliably (hello ModelOps!). Data resilience will be a must-have piece of that puzzle. In my next post, I will talk about the 3rd part of the AI ModelOps Trifecta - Model Deployment & Monitoring.
Hewlett Packard Enterprise acquires Pachyderm - https://www.hpe.com/us/en/newsroom/press-release/2023/01/hewlett-packard-enterprise-acquires-pachyderm-to-expand-ai-at-scale-capabilities-with-reproducible-ai.html
HPE Acquires Zerto For $374 Million- https://www.zerto.com/press-releases/hpe-to-acquire-zerto/
Salesforce Acquires Own Company for $1.9B in Cash- https://www.owndata.com/newsroom/salesforce-signs-definitive-agreement-to-acquire-own-company
Rubrik to Acquire Datos IO to Expand Cloud Data Management Offerings- https://www.rubrik.com/company/newsroom/press-releases/18/rubrik-acquire-datos-io-cloud-data-management
AWS acquires CloudEndure disaster recovery, backup services- https://www.techtarget.com/searchdisasterrecovery/news/252455843/AWS-acquires-CloudEndure-disaster-recovery-backup-services
TLDR-
What’s driving adoption of automated backup and recovery in AI?
Reason #1- AI data isn’t static, it flows through complex pipelines that mutate at every stage. Without automated version control, reproducing results or rolling back mistakes becomes a nightmare.
Reason #2- Ransomware is now a boardroom threat. When AI data includes PII or proprietary IP, losing it isn’t just bad, it’s business-ending. Secure, air-gapped backups are becoming non-negotiable.
Reason #3- Cloud-native AI is messy and across AWS, GCP, on-prem, and SaaS tools. Enterprises want one cloud-agnostic backup layer that works across this sprawl without lock-in.
Reason #4- New AI regulations demand traceability. If a model made a decision six months ago, you better know which dataset trained it. Backup + versioning is the only way to comply at scale.
You've done a good job of framing the urgency and surfacing under discussed pain points like ones around pipeline fragility, rollback blind spots, and the inadequacy of legacy infra for ML-specific needs. But some observations-
1. In practice, very few orgs outside hyperscalers or top AI labs face these problems at that scale today
2. DVC and LakeFS lack full backup semantics but they’re often stitched together with Airflow, S3 versioning, or even Git LFS in well run infra teams. Saying they don’t offer full-fledged backup is accurate, but is actually dismissive of how power users actually extend them
3. The big enterprise shift I’m seeing is that AI governance is no longer about what model did we use, but what decision did this model influence, based on what data. That means you need data backups + prompt logs + retraining checkpoints all tied together. This convergence is worth a deeper dive.. and maybe a handful are solving this
4. Backup sounds great until your CFO sees the AWS invoice. There’s a trade-off between granularity, retention period, and cost here
Lays a good foundation to the problem deep dive ngl, but it needs a level up for a proper thesis