
#121- It’s not the model, it’s the memory
As LLM performance converges, the next $1b opportunity will be in memory. This post explains why persistent, policy bound memory will be the missing layer in enterprise AI infra
Every copilot forgets. That’s the problem.
We’ve made it easy to talk to machines, but nearly impossible to build systems that remember us. As enterprise GenAI deployments grow, it’s memory and not models that’s failing. And enterprise buyers are asking the wrong question: "Which model is best?"
In reality, the delta between top tier LLMs, although exists, but is shrinking. Model quality alone is no longer the core differentiator. Retrieval augmented generation (RAG), fine tuning, even orchestration logic are now default tools. Everyone has them. Everyone will keep swapping models in and out.

What remains defensible? Memory.
Not logs. Not traceability. But usable, persistent, trustable memory.
Establishing the contextual memory layer for AI systems
I believe the next $1bn infra company won’t just orchestrate agents or serve models. It will own the context layer. A dynamic, queriable memory system that plugs into any GenAI application and preserves context across sessions, tools, workflows, and identities.
It wont be right to categorize it as a fancy vector DB. It’ll lie at the intersection of four primitives:
Memory persistence- What was said, by whom, when, and why?
Policy-bound recall- Who can remember what? And under what conditions?
Structured recall- Memory shaped by industry-specific schemas and language
Observability + audit- Memory is useful only if it’s governable
Why does this matter now?
Because AI systems aren’t stateless anymore. They’re expected to learn over time, work across departments, stay within guardrails, and expose what they remember when asked.
Right now, no infra layer does this well.

The transition from fragmented agents to unified memory
For most copilots context dies when you refresh the page, close a tab, or switch agents.
So companies start duct taping together RAG pipelines, chat histories, embeddings, and caches. The result? A brittle mess of partial memory with no consistency, no permissions, and zero accountability.
I think there’s a clean slate, whitespace opportunity to build MemoryOps as a core layer-
APIs to store and retrieve context across LLMs
Dashboards to monitor memory usage
Guardrails to apply policy and forget where needed
And adapters to conform to domain-specific structures (healthcare, BFSI, legal, infra)
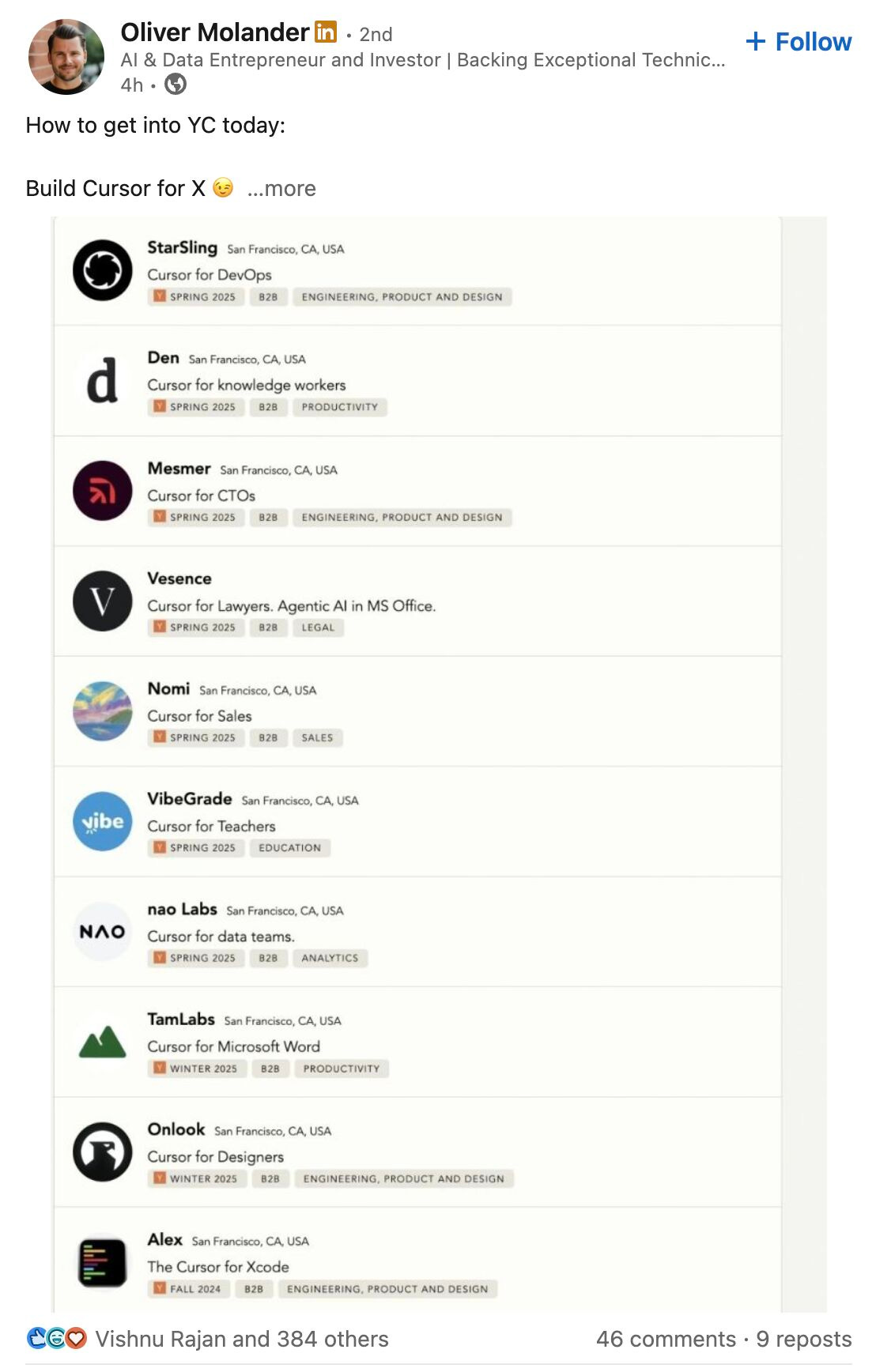
This is where most copilots, even the impressive ones like GitHub or Cursor start to break down. Cursor, for example, is a purpose-built, context-aware coding copilot that excels inside the IDE. But once you leave a file, close a project, or shift to a new domain, the memory ends.
You’ll find a whole genre of "Cursor for X" startups now emerging from legal to ops to infra. They’re all pointing to the same need: persistent, portable, governable memory. That layer doesn't exist yet. But it should.
Memory infra maturity is from duct taping to building the trust layer
Most enterprise AI systems today run on duct tape. A patchwork of RAG pipelines, chat logs, embeddings, and caches loosely stitched together with zero policy, no structure, and brittle reliability.
The next evolution is schema aware memory structured by domain and shaped by the way companies actually work. But the final frontier is trustable memory: observable, opinionated, governed by default.
The winners here will move away from plugins to be real platforms. And memory will decide if AI scales or stalls.
Is this just data governance?
Not quite. I wrote recently about how data governance will underpin AI adoption: securing access, tracking usage, enabling redaction. That layer is about controlling data inputs and model behavior.
This is one layer up. This is about governing stateful AI systems over time.
Governance tells you what happened. Memory lets you keep operating without starting from scratch. They are complementary. One secures the pipe. The other builds the brain.
What could this enterprise memory layer look like?
Some wedges I expect:
Memory as a Service API for app dev teams
Private memory vaults for regulated verticals (health, finance, infra)
SDKs for structured memory (Remember this CRM deal thread/Recall past anomalies from these machines)
Access logs + replay tools to enable safe debugging of agentic workflows
You could imagine players like LangChain, LlamaIndex, Pinecone, and others evolving here. But these players were built for search, not state. LangChain wasn’t designed for persistent memory management. Pinecone lacks policy, structure, and temporal semantics. None of them are equipped to become the trust layer enterprises need.
The first real enterprise memory player will do two hard things:
Design trustable recall infra
Enforce memory policies at scale

GenAI 2x2 - Persistent, high-trust memory in domain-rich systems is missing

Field notes - what beta readers asked/pushed back on
I showed early versions of this thesis to founders, infra teams, and enterprise buyers. Here's what came back, almost verbatim (edited for brevity)
1. Is policy bound recall just fancy RBAC?
No. It starts as RBAC, but gets deeper. Imagine context that expires, travels downstream but not upstream, or is filtered based on purpose. This needs policy engines, and runtime interpreters, etc2. What do you mean by industry specific schemas? Templates or domain expertise?
Founders who build will guide using the problem they solve - the space is big enough for all sorts of products. But I’m thinking more than templates, like opinionated, structured formats that enterprises can tune. Enterprises won’t want to build from scratch3. Can’t LangChain/Pinecone just pivot?
They’ll def try. But their DNA is built around search, not state. Retrofitting policy-bound recall, TTL, audit, and multi agent orchestration is non-trivial. The winner here will build ground up for trust4. ChatGPT will builds this
This is technically what a VC should tell founders, but fair. It is entirely possible that OpenAI or Anthropic makes memory a core platform feature. But the catch is that most enterprises won’t trust their stateful memory layer to a general purpose, closed source, opaque black box. The winning memory infra will & has to be neutral, pluggable, policy-first. It can not be vertically integrated into a proprietary model stack5. So the memory layer isn’t just saving chat history?
No, it’s schema aware. It understands legal documents vs medical records vs code differently, because the structure matters6. Isn’t access control already solved?
This isn’t just “who can see what” it’s “why can they see it, and for how long.”
Think time-bound, purpose specific recall with automatic expiry not just RBAC7. What’s memory shadowing?
It’s maintaining parallel, personalized context for different stakeholders like a PM and engineer interacting with the same product spec, but each getting different memory views based on what they care about
Curious if your infra is memory-ready or stuck in patchwork?
I built a free, DIY MemoryOps Audit. Score yourself across 5 dimensions and see if your infra is stateless, patchwork, or memory-ready.
My thesis on memory infra as the next foundational layer
Why does this matter? Because memory infra has the characteristics of a generational infra business:
Embeds deeply across teams and workflows
Compounds knowledge over time
Creates switching cost through trust, policy, and recall
Becomes invisible, but indispensable
By 2027, memory infra will be table stakes in every serious enterprise GenAI deployment. When memory breaks, copilots repeat themselves, hallucinate, or forget critical context. More than inefficient, it’s dangerous. In healthcare, it means missing patient flags. In customer service, it means misrouting and churn. In legal ops, it means real risk exposure and liability. These are structural cases. The companies that own this layer will become the control plane for how context flows in hybrid human-AI systems.
When memory works, workflows shift. Agents debug each other. Context travels across tools and teams. It unlocks platform primitives like purpose bound recall or event triggered memory wipes.
This won’t be obvious. Because memory is invisible when it works. But every enterprise GenAI buyer we know is hitting the same wall:
Copilots that don’t remember
Memory systems that leak
No redaction, rollback, or accountability
If you're building this, and you're opinionated about what should be remembered, who can recall it, and under what rules, I want to talk, I want to be the first cheque.
The memory company will be a platform with its own primitives: context persistence, policy-first recall, and structured observability. Because until it does, every agent resets to zero. Every workflow rebuilds context from scratch. And enterprises will keep blaming models instead of fixing memory.
If I’m wrong, it’s because foundation models themselves evolve memory-like persistence, or platforms like OpenAI become good enough for most use cases. But I still bet on this wedge because trust, auditability, and schema structure can’t be solved top down. They need infra-native design.
And we’ve seen this before. Monitoring wasnt obvious until Datadog, identity wasnt obvious until Okta, memory will be no different. It’ll feel like trust by default. And it’ll quietly reshape how every enterprise runs AI.
Read my recent posts-
The AI trust crisis is already here - but nobody is talking about it
Where I’d invest in AI infra today - 3 key spaces
AI Data Preprocessing- clean input is the foundation
AI data Backup & Recovery- disaster-proofing AI systems
AI Deployment & Monitoring- keeping models alive in the wild
The 5-Point AI Infra Filter- how I spot weak wrappers vs real infra